In loving memory of Immutable.js
Using Immutable.js and trying to make some sense out of its memory usage.
Any JavaScript spaghetti worth its salt won't keep track of its objects references or their updates. These are things that happen between the mind of a chef and the ether of a planned portion with lots of defensive copying. Immutable.js aims to reduce these portion sizes to match the ones in fancy restaurants while avoiding ingredients like:
JSON.parse(JSON.stringify(obj))
To try out this new pepper lets open the developer tools in a new tab and sharpen our sour-sweet tooth.
How many calories has the appetizer ?
In order to measure the amount of memory that Immutable.js uses by itself lets marinate it in a quick and dirty formula:
- Open the devtools
- Define a simple array with a single item in it and print it to the console
let test1 = [1337]; console.log(test1);
- Measure the memory usage (memory tab of the dev tools)
- Load Immutable.js directly into the console (copy pasting its minified source directly into the console)
- Define a simple list with a single item in it and print it to the console
let test2 = Immutable.List.of(1337); console.log(test2);
- Measure the memory usage again
The key points are 3. and 6. so lets do it and take a look into the memory info. For these measures I am using Firefox Developer Edition 53.0a2 (2017-03-05) (64-bit) in OSX Sierra.
After point 3. I have 2.11MB of used memory with the following layout:
- scripts: 37KiB (347 objects)
- strings: 362KiB (9685 objects)
- objects: 813KiB (11325 objects)
- other: 849KiB (18365 objects)
This is for nothing but an empty tab with devtools opened after point 3. in the magic formula.
Now lets load Immutable.js raw minification and run the rest of the steps.
After point 6. I have 2.53MB of used memory with the following layout:
- scripts: 248KiB (1717 objects)
- strings: 384KiB (10252 objects)
- objects: 904KiB (12618 objects)
- other: 933KiB (19984 objects)
Immutable.js makes the memory usage go up from 2.1MB to about 2.5MB. That's around 0.4MB just to load the minified Immutable.js in memory.
Lets keep this value as a reference in further tests. I am keeping these memory snapshots also for further reference.
How can we leverage the juice from these 0.4MB into our secret sauce ?
A list of many secrets
Immutable allows the discerning chef to cook with well defined ingredients. You can define your own data types and use them as immutable everywhere you want to. To do that the Immutable.Record is their provided interface.
The following code uses it to define a data type for a 2D point, with X and Y coordinates, and then create some points with it.
const Pt = Immutable.Record( { x: 0, y: 0} );
const pt1 = new Pt(); // uses x: 0, y: 0 by default
const pt2 = new Pt({ y: 123 }); // uses x: 0 by default
const pt3 = new Pt({ x: 123, y: 321 }); // uses your provided valuesFast-food junkies could do the same in straight JS with the simpler approach:
function PtJS(x = 0, y = 0) {
this.x = x;
this.y = y;
}
let jspt1 = new PtJS();
let jspt2 = new PtJS(0, 123);
let jspt3 = new PtJS(123, 321);Some might even argue that they are not wasting the memory that Immutable is. Master chefs are always looking for opportunities to learn, to study and to teach.
Now for a simple test, create a list with 10000 of those 2D points and compare memory readings of the Immutable approach with the plain JS approach.
First the plain JS approach (lets assume the constructor is already created as above).
let testArray = [];
for(let i = 0; i < 10000; i++) {
testArray.push(new PtJS());
}
After measuring this in the Memory tab we get 2.92MB in this layout:
- scripts: 228KiB (1692 objects)
- strings: 384KiB (10251 objects)
- objects: 1MiB (22688 objects)
- other: 888KiB (19990 objects)
That seems fair, we get an increase of about 390KiB in comparison to our previous measurement. That should be enough motivation to roll our Chefs Knives suitecase of Persistency and do it in Immutable style to measure it on top of this 2.92MB already in use.
const defaultPt = new Pt();
const testLst = Immutable.Repeat(defaultPt, 10000);After measuring this in the Memory tab we get 2.91MB. This is a decrease of about 10KiB from our previous memory usage. How is this possible ? Is the data even there ?
testLst.first().x;
// returns 0
testLst.size();
// returns 10000Yep, it's all there. Immutable.js allows you to take good care of your memory, but as with all sharp knifes you need to know how to avoid hurting yourself. Lets dive a bit further to understand what is going on and how to master these data structures.
Master Chef Mystery Boxes
One common misconception about immutable data structures is that there is a lot of useless copying being done. In fact this is so common that there are even JS libraries based on it. Playing with the flavour of common things note the most typical data structure in functional languages.
The single linked list.
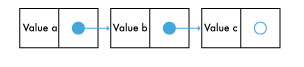
Supposed that this is a immutable list. It is not possible to add, remove or change its values without returning a new version of it.
Does this mean that we need to copy all of it when we need to put a new value in it ? Not necessarily. We can just create the new list item and make sure its pointer is targeting the beginning of the original list.

This works because the list is immutable, we know for sure that the original list won't change so it is possible to reuse its values, no copying is involved in this.
As before, our new immutable list is again defined by its first value, which in this new case is our new value.
Master the simple cuts first
Many operations are possible on our immutable single linked list that leverage the fact that it is an immutable list.
Operations like head (return the first value in the list) and tail (return all the items in the list except for the first) are almost instantaneous to implement. For head we just return the value of the first item and for tail we just return the first item pointer value (which is an immutable single linked list, in this case, our original 3 value list).
Concat
Joining two lists is one of those simple operations that is worth your time and attention in order to understand it. If we have 2 different immutable lists that we want to join we need to go to the first list and adjust the last pointer of the last item to point to the first item of the second list.
Here it is in pictures:
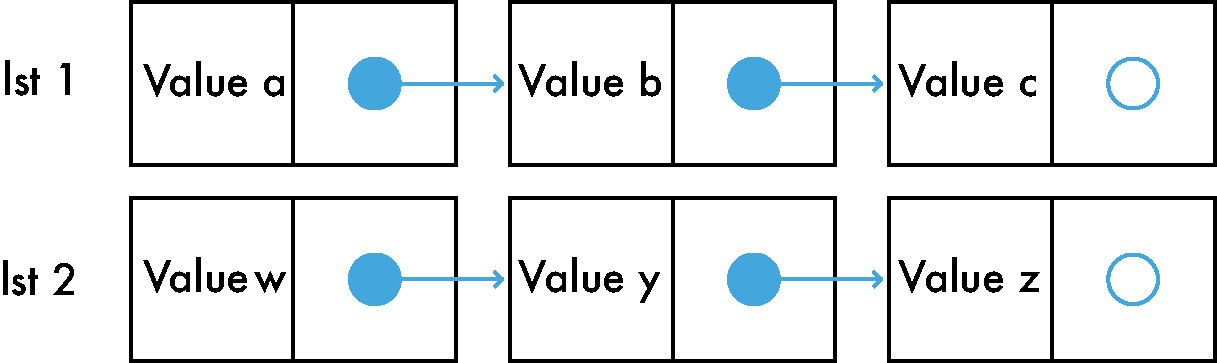
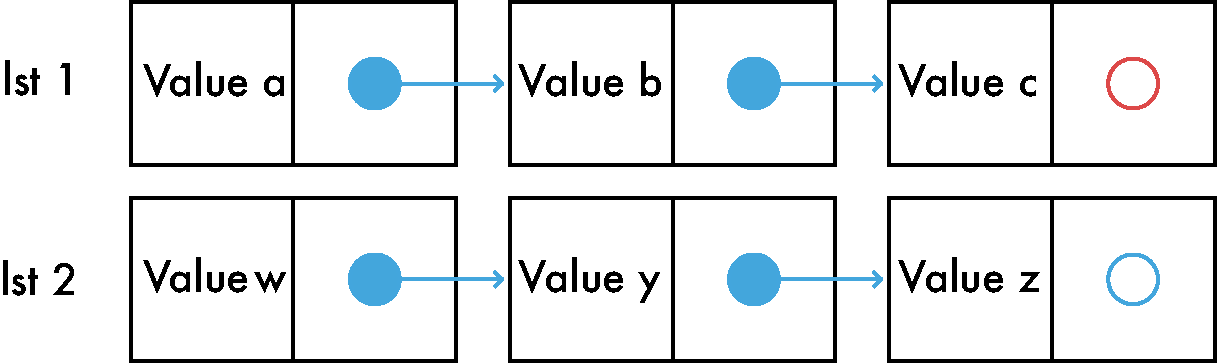
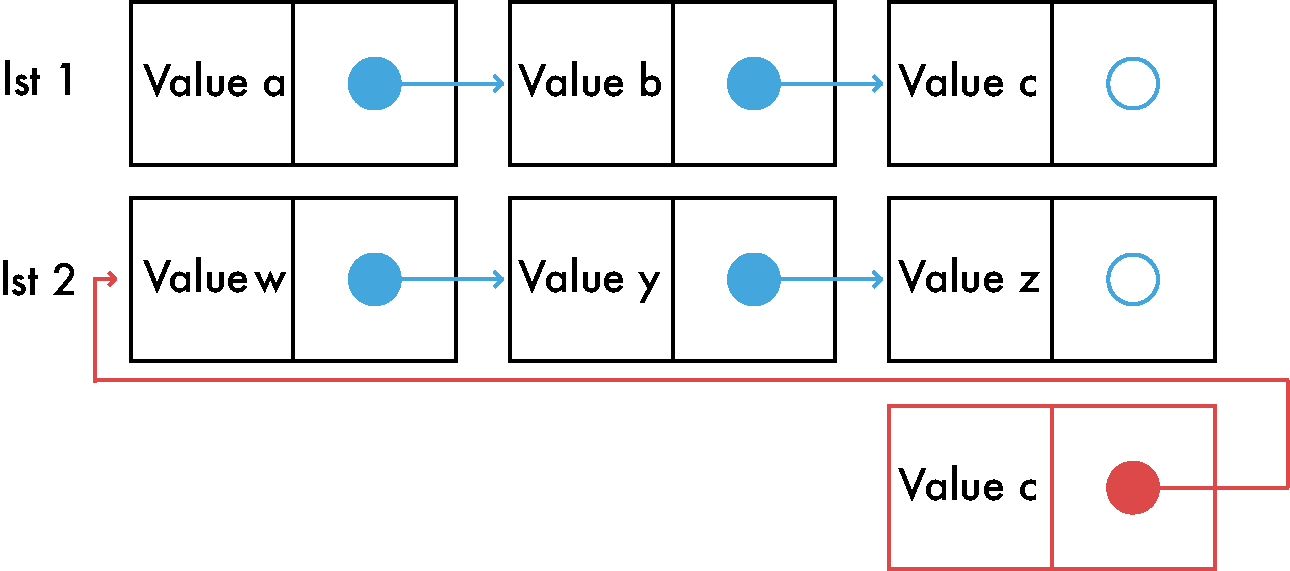
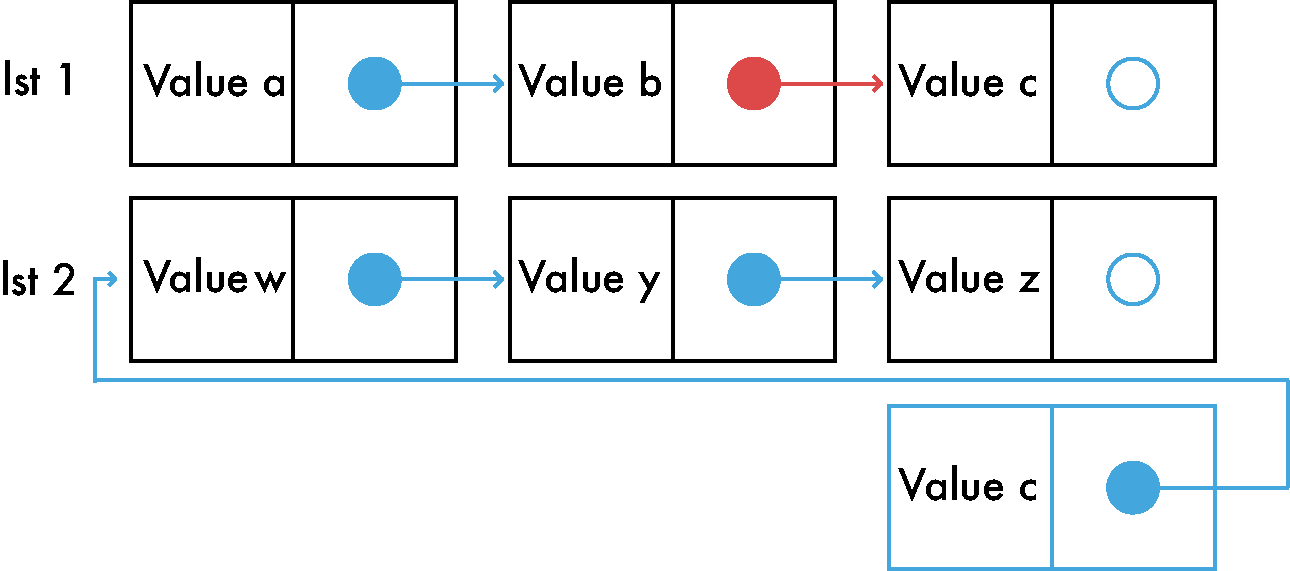
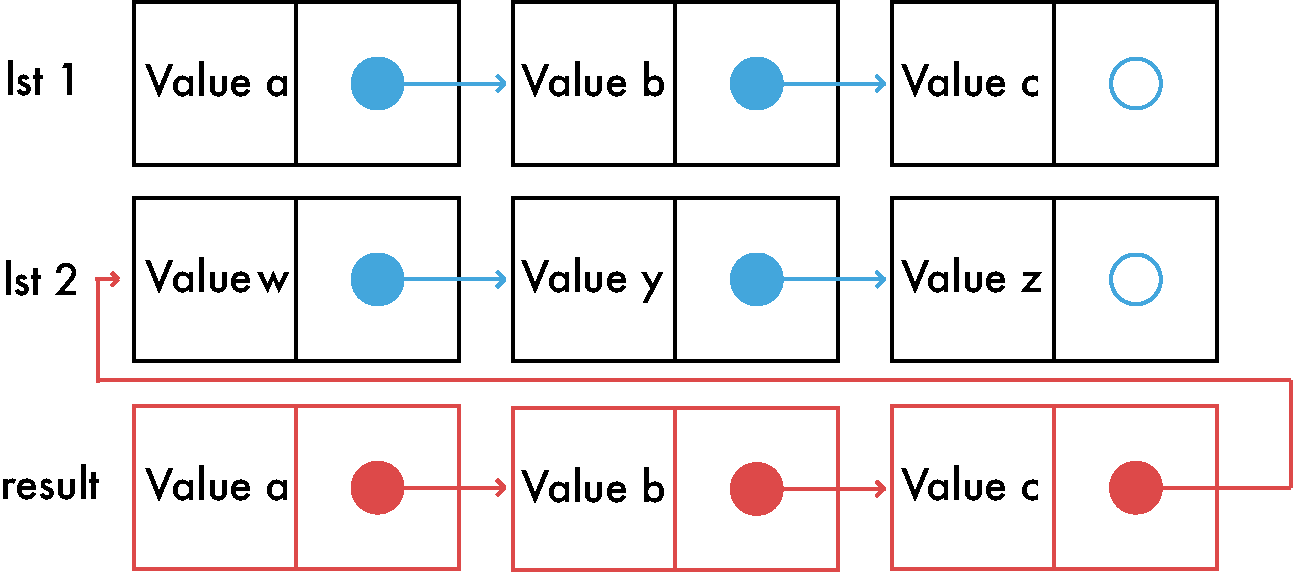
Concat is a heavy operation, it mostly depends on the size of the first list. There are a few tricks to make it faster.
To keep it simple I am not going to go much more into this and move to the point.
The best recipe is made of many subrecipes
The list holds data. That's why it's called a data structure. Now what if instead of directly putting our data in each list item we could instead just point to the data ? Like this:
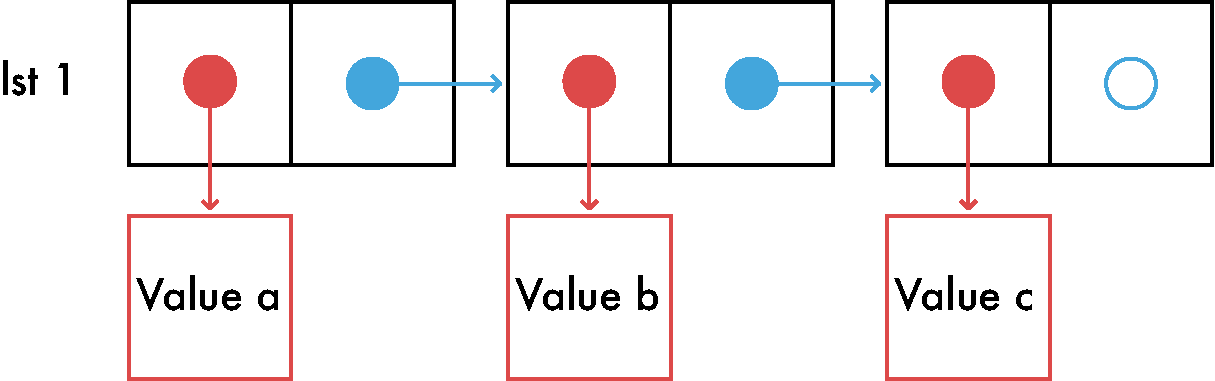
The list effectively now holds a way to reach each value instead of the real values. We can get more generic and greatly simplify it by saying that in each list item there is a recipe to reach each value. In the above picture this recipe generalization is represented by the red arrows.
Let me try to simplify it with the hope that it might stand out the intended purpose.

The term recipe is not chosen by chance: it represents something that must be done to produce the value that the list item holds.
If we follow the recipe in each item we can get to the intended values. For instance, suppose that this is a list of JS Number's, a good recipe to produce the value would be to just call Number() on the data. If it was a list of String's, a good recipe would be to call String() on the data. This also holds for very complex values, say this is a list of balanced tree's, or your favourite custom complex data type, a recipe is the way to construct the value, could just be following a pointer but perhaps that would not be a very useful constructor due to being too general.
Lazy concat
In our previous look into concat we noticed that it was a heavy operation, requiring a full copy of the first list that we want to join. When working with immutable data there are only a few of these "heavy" operations that do need a full copy.
Now that we are taking quality steps as chefs how about we use a recipe for concat ?
Instead of doing a full copy of the first list, just copy the first element and make it point to a recipe. That way, no matter the size of the lists, concat would be done in a single operation (the first item). Here it is in a picture:
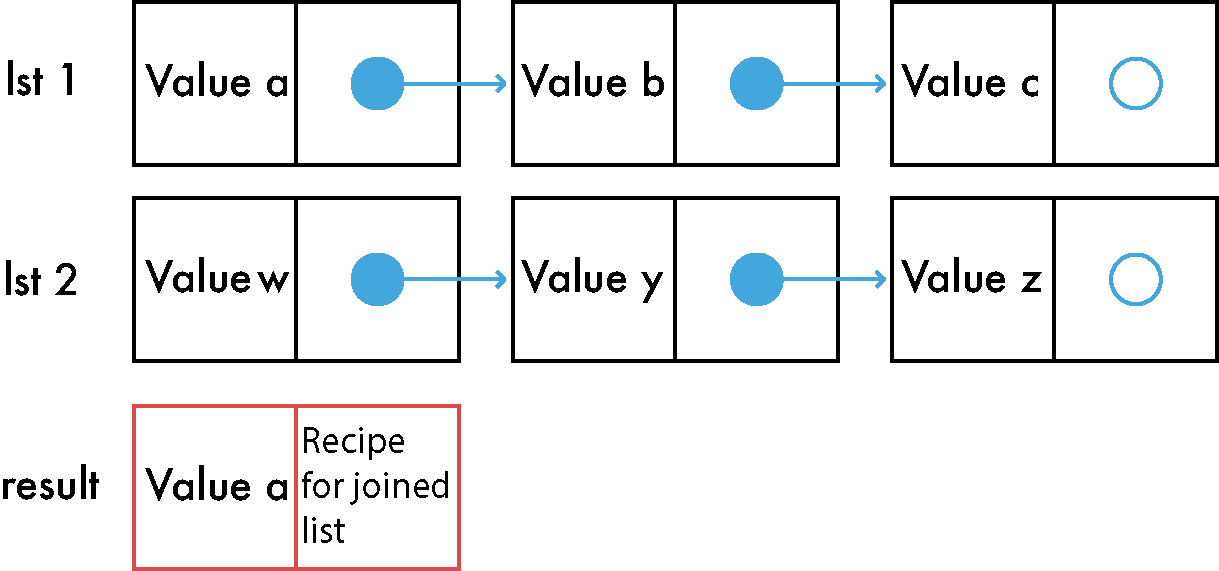
Now if we need the second element of the list the recipe will be followed to get it.
That is a simple recipe: copy the first list up to the needed value, if the copying is done but the intended value is not yet reached then start going through the second list values (without copying them). In the case we want the 2nd value of a concat'ed list a single copy will happen because we already copied the first item when concat was called. This is a case where the recipe is itself the whole concat operation, meaning that it will only copy until the end of the first list and after it will use the reference of the second list.
This recipe approach is usually known as laziness and typically enhanced with a cache of results to avoid copying and constructing the same values over again (this caching approach is known as "memoization").
Cuisine du monde
Immutable.js makes good use of these techniques to avoid doing work when necessary and unnecessary copies. Their approach is lean and well thought, clearly separating the values from the way they are traversed.
Lets look at our Immutable approach again:
const defaultPt = new Pt();
const testLst = Immutable.Repeat(defaultPt, 10000);
testLst.first().x;A few things stand out:
- We are always using the same reference defaultPt instead of creating a new value in each item.
- This is possible thanks to immutability, if we change it we are effectively creating a new value and a new list.
- Immutability encourages reutilization and is typically a GC friendly approach.
- Repeat just returns a recipe (thunk)
- No heavy work is actually done, it just returns a way to access and construct the values
- We used 10000 but could have used infinite with no performance or memory hit
- Work is only done when values are being requested and only up until them.
Immutable.js also uses a few other tricks to speed up common operations. For instance their List approach uses deques, which means that it keeps your list split in two, so [1,2,3,4,5,6] is kept by Immutable as [1,2,3] and [6,5,4] (reversed rest). This is a very simplified explanation of it, but in practice it allows for very fast insertions in the beginning and end of the list (faster than JS arrays).
Conclusion
Immutable is certainly a different way of doing JS. Given the normal tendency JS coders have to lean more towards object oriented concepts, immutable feels like the schrodinger's immigrant in a foreign land.

I hope this post was in any way useful to you. Immutable sure is a fun library to get to know and work with.